Dashboard Tutorials
Basics
In this lesson you will
- Create a Grafana dashboard
- Add visualizations based on the collected data
- Filter the data to represent specific information
We have already set up a basic Grafana Instance on the same server the database storing the data lies on. This includes adding the database holding all the collected data as a data souce so that you can directly start creating a dashboard.
Lesson steps
Creating a dashboard
- Connect to the Grafana server using the following link http://141.24.194.106:20203.
- Log in using the credentials we gave you.
- Click
Dashboardson the left. - Click
Newon the right and thenNew dashboard.
Adding a visualization
- Click
Add visualization. - Select
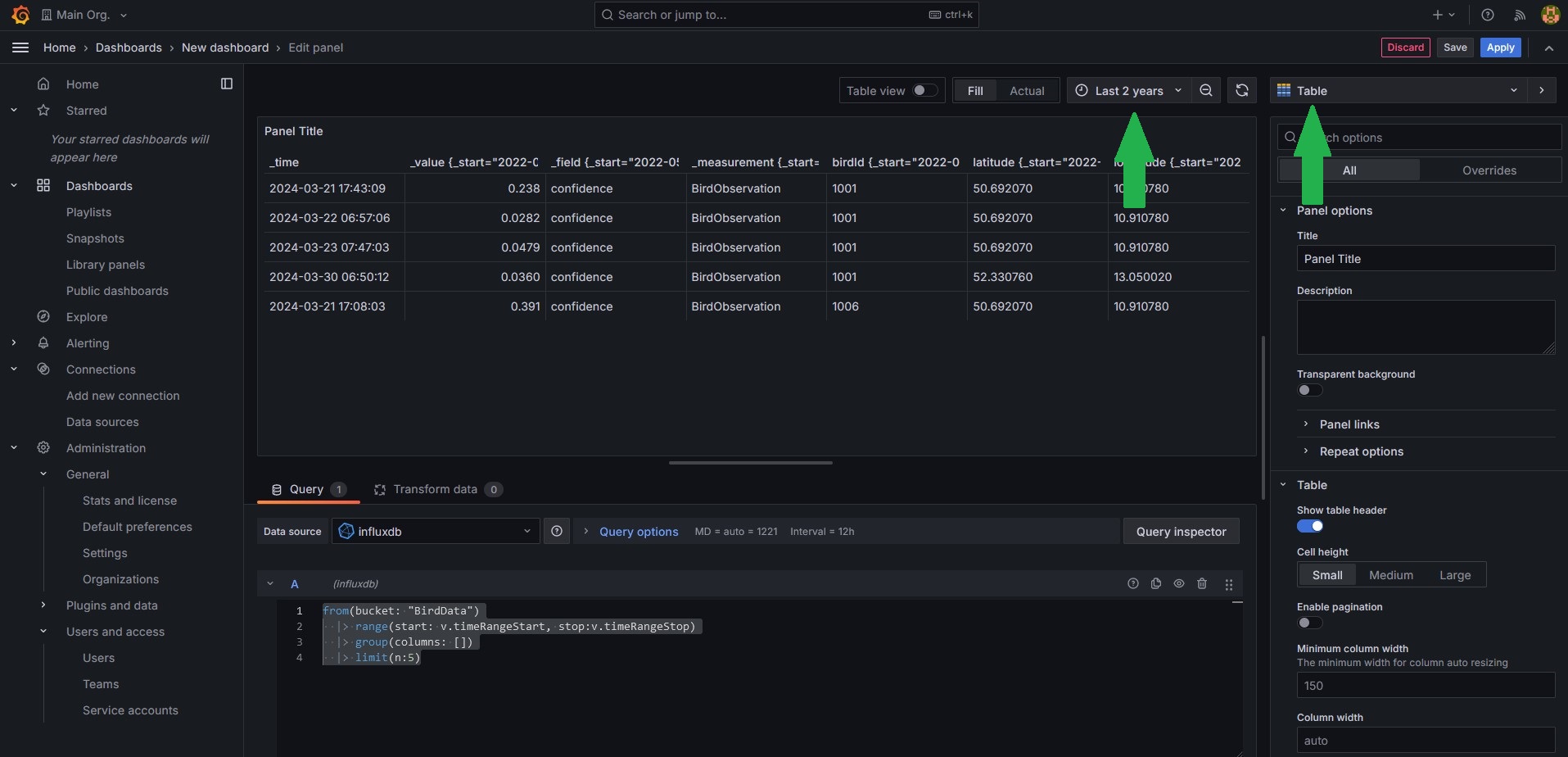
influxdbas the data source. - First we want to see just the raw data, so set the visualization type in the upper right corner to
Tableand set the time frame toLast 2 years. - Now enter the following query into the text field at the bottom.
- When your done click save, give your dashboard a name and click save again
Adding filters
As you can see, the data contains the confidence value. Since the AI model doesn't have an output for no bird detected it will always classify some bird for every measurement. If there is indeed no bird in the sample it will usually show by a very low confidence. So it would be good to filter out entries with a confidence below a certain threshold.
- Go to the Dasboard settings(the gear at top right) and select the tab
Variables. - Click
Add variable. - Create a variable with the type
Custom, give it a name(how you refere to the value in your query, for exampleminConf), a label(Name that will be displayed in the dashboard) and enter some boundaries in custom options(for example0.9, 0.75, 0.5, 0.25, 0). - Click
ApplyandCloseat the top right. - Click
Addat the top right and selectVisualization. - Select as visualization type again a
tableand copy the code from earlier. - Add a filter command between the range and the group command. The full query should look something like this.
- Click
Applyin the top right and compare how the two tables look, especialy forminConf=0andminConf=0.9. - You can edit a visualization by hovering over it with the cursor and clicking at the three dots appearing in the upper rigth corner and then clicking
edit. Do that for both tables and change their names()On the right side underPanel optionsthe fieldtitelso that they are distinguishable. Dont forget to save the dashboard once your done.
Adding a proper visualization
While the raw data might be useful, what we want from a dashboard is seeing important values with ease. So lets add a counter how many birds were recognised with the given confidence
- Add another visualization, this time of the type
Stat - You can reuse the query from the filtered table.
- Instead of limiting the number entries we want to count them. Replace the
limitcommand with the count command. It sould look like this: - Name the visualization, apply and save.
Another interesting stat would be what birds were recognized the most. Lets add a visualization for that.
- Add another visualization. The are some types you can choose from, but this tutorial will use the
Bar gauge(Hint: SelectTableas the type to understand how the changes in the query effects the data every step) - For the query, we can use the first three lines from the code above since that essentially just returns all measurements that have the required confidence.
- Next, we want to group all measurements that were of the same bird. We can do this by
|> group(columns: ["birdId"]). This creates groups of measurements with the sameBirdID. You can imagine a group as a simple table. - Since we want to know how often each bird was detected we add
count(). This counts the measurements in every group and replaces the group content with that value. - For the
Bar gaugewe need the data in a single group, but right now every bird has its own group. We fix this by addinggroup(). - Finally we want the birds in order, therefore we need to sort the current group. We can do this by adding
sort(desc: true). This sorts our group entries in descending order, meaning the bird that was spotted the most often should be listed first. - On the right side under
Value optionschangeCalculatetoAll values - You can customise the visualization if you want. For example changing the orientation to horizontal makes it easier to understand. Dont forget to save once your done.
- As you might have noticed, instead of bird names the bars are labled with the IDs. This is due to way the data is stored in the database. For now its fine, but if you're insterested you can check here which ID belongs to which bird.
Accesing an external ressource/Adding labels
In the last task we had the problem that the measurements in the DB only holds the IDs of the classified bird, but not the actual name. But fortunatly we have a table holding the IDs and corresponding names. In this step we want to load the data into the query and modify the result form the last task in a way that the bars are labled with the actual name rather than the ID.
- First, reopen the visualization by hovering the cursor over the diagramm, clicking the three dots in the upper right corner and selecting
edit - Bind the current query result to a variable. You can do this by choosing a name(we will use
leftsince we will perform a left join later but any name is valid) and writingname=in front of thefrom(bucket: "BirdData"). - Next add the following three lines at the top of the query. These packages provide the functions to load and transform the table from earlier into a flux query object
- Now we first need to load the csv using the following line. This simply performs a
HTTP getrequest to github to the same ressource that is linked to earlier. (You might notice that the links aren't identical. This is due to github usually providing a visualy enhanced file. But since we need the raw data we access that in this query directly. If you're curious you can open the link from the sample to see the raw data yourself) - For now the csvData variable only holds the data as a string(the datatype for text). To transform this to a proper flux query object we need to parse it. Fortunatly there is a already defined function for that in the
csv-package we imported earlier. Add the following line to your code. Note that we bind the result to the variablerightas the second part of our join operation. - Now that the label data is loaded and parsed we can combine it with our earlier result. To do that we need to perform a
left joinon the earlier result. Just copy the code below into your query. You can read this if you don't know what ajoinis. - The only things left to do is clarifying what data to show and to sort that data. We can do this by removing all columns that are unnecessary and keeping only the
nameand the_valuecolumns of ourjoinresultresultand sorting after that. Your query code should look like this.import "csv" import "experimental/http" import "join" csvData = string(v: http.get(url: "https://raw.githubusercontent.com/Science-Camp-TUI/birdnet-mini/main/idToLabels.csv").body) right=csv.from(csv: csvData, mode: "raw") left=from(bucket: "BirdData") |> range(start: v.timeRangeStart, stop:v.timeRangeStop) |> filter(fn: (r) => r._value > ${minConf},) |> group(columns: ["birdId"]) |> count() |> group() |> sort(desc: true) result=join.left( left: left, right: right, on: (l, r) => l.birdId == r.BirdID, as: (l, r) => ({l with name: r.GermanName, _value: l._value}), ) result |> keep(columns: ["name", "_value"]) |> sort(desc: true) - You can customize the visualization. Dont forget to save once you're done.
Free working
Now that you have some basic knowlege about writing queues you can add visualisations for other stats you think are important freely. Some possible examples are
- What is the relation between the detected bird species(Pie chart)
- Add a filter for a specific bird type
- How often was the selected bird detected(Stat)
- At what times over the day was the bird detected(Time series)
- Where was the bird detected(Geomap)
- Add a filter for the different measurement locations
- All already mentioned things but filtered for the station
- And a lot more...
If you need help you can always ask the instructor. A helpful ressource is the flux documentation for general questions.